Keras OCR CNN RNN
2021.11.19 更新
弊社では、AI・ディープラーニングの応用研究に取り組んでいます。自社の研究活動のほか、お客様の研究テーマをアウトソーシングしていただく委託研究も行っています。
さて近年、AI OCRが発展したことで、手書き文字であっても画像の文字認識精度が格段に高まりました。それにともなって、RPA関連など多くのOCR製品やサービスが提供されている状況です。またコロナ禍をきっかけにテレワークが増えたことや、DX推進などで、今後もさらに活用がひろがりそうです。
そんなAI OCR技術として今回は、Keras code exampleから「OCR model for reading Captchas」を題材に、サンプルの動作検証と、簡単な応用実験を試したいと思います!
OCR model for reading Captchasの概要
まずOCRでは一般に、請求書などの紙文書をスキャンした画像データから、そこに書かれた文字をテキストデータとして抜き出します。
基本的な仕組みは、①文書のレイアウトを解析して文字部分を取り出し、②それに対して機械学習などのアルゴリズムで文字データを認識する、という流れになっています。
OCR model for reading Captchasは、セキュリティ目的でよく使われるCAPTCHA画像を、横書き1行の文字列画像として読み出そうとするものです。
さらにCAPTCHA画像ですから、人だけが読めるように文字に加工がされていますので、それでも文字として正しく読み取れるのかを試みる点で、たいへん面白いサンプルになっています。
文字データを認識するためのアルゴリズムはいろいろありますが、ここではCRNN(CNN + RNN)とCTC損失関数を使ったシーケンス認識(Sequence Recognition)を用いています。
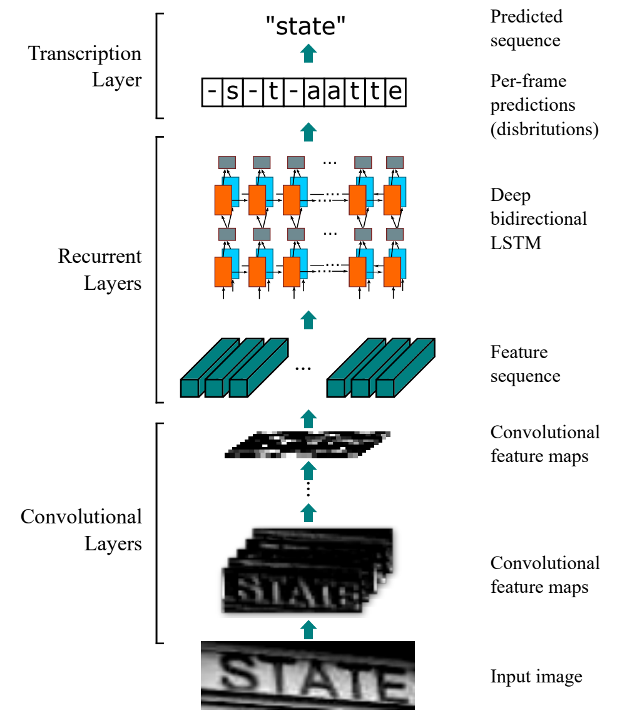
出典: https://arxiv.org/abs/1507.05717
シーケンス認識では、1行の文字列画像を系列データとして扱います。レイアウト解析によって、あらかじめ1行の文字部分が切り出されているケースに対応できます。これに対して、MNISTのサンプルでよく見かける文字認識タスクは、レイアウト解析で1文字の画像に切り出されたものに対応します。

サンプルの動作検証
さてCAPTCHA画像をダウンロードして、サンプルプログラムを実際に動かしていきます。CAPTCHA画像は全1040枚あり、9:1で学習データと検証データに分けておきます。
ここでいくつか学習データを描画してみます。画像の上部にあるのが正解のテキストです。人であればだいたい読み取れるかなと思いますが、個人的には間違えてしまいそうなものもあります。

次にモデルを構築します。モデル構造は下記のとおりです。モデル前半のCNNで画像特徴を系列データにしています。それを双方向RNNに渡して、その出力から文字列を予測して、CTC損失を求めていることが見てとれます。
Model: "ocr_model_v1"
__________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==========================================================================
image (InputLayer) [(None, 200, 50, 1)] 0
__________________________________________________________________________
Conv1 (Conv2D) (None, 200, 50, 32) 320 ['image[0][0]']
__________________________________________________________________________
pool1 (MaxPooling2D) (None, 100, 25, 32) 0 ['Conv1[0][0]']
__________________________________________________________________________
Conv2 (Conv2D) (None, 100, 25, 64) 18496 ['pool1[0][0]']
__________________________________________________________________________
pool2 (MaxPooling2D) (None, 50, 12, 64) 0 ['Conv2[0][0]']
__________________________________________________________________________
reshape (Reshape) (None, 50, 768) 0 ['pool2[0][0]']
__________________________________________________________________________
dense1 (Dense) (None, 50, 64) 49216 ['reshape[0][0]']
__________________________________________________________________________
dropout (Dropout) (None, 50, 64) 0 ['dense1[0][0]']
__________________________________________________________________________
bidirectional (None, 50, 256) 197632 ['dropout[0][0]']
__________________________________________________________________________
bidirectional_1 (None, 50, 128 ) 164352 ['bidirectional[0][0]']
__________________________________________________________________________
label (InputLayer) [(None, None)] 0
__________________________________________________________________________
dense2 (Dense) (None, 50, 21) 2709 ['bidirectional_1[0][0]']
__________________________________________________________________________
ctc_loss (CTCLayer) (None, 50, 21) 0 'label[0][0]'
'dense2[0][0]
==========================================================================
Total params: 432,725
Trainable params: 432,725
Non-trainable params: 0
__________________________________________________________________________
学習をまわすと、Eeary Stopping (patience=10)で32エポックまで学習され、だいたいサンプルと同じような結果が得られました。検証データによる予測結果を描画してみると、何とこの例だとすべて正解しています!

MNISTで検証してみた
次に、一般の手書き文字認識に近づけた検証をするため、MNISTで横1行のデータを生成して同様に試してみました。
MNISTのデータは1文字単位の数字画像なので、横に並べて、1行5文字と10文字の画像データを生成しました。ちなみにシーケンス認識では、予測できる文字列長は可変にできます。先の検証と条件を合わせるため、それぞれの1000枚ずつ生成し、同様に9:1で学習データと検証データに分けておきます。
同じモデル構造を用いてそれぞれ学習を行い、検証データによる予測結果を描画しました。一部、ちょっとクセが強すぎるでしょ?と思うケース以外、概ね正解できているのではないでしょうか。
MNIST 5文字による予測結果

MNIST 10文字による予測結果

自分で書いた手書き文字を認識させてみた
最後に、このMNISTで学習したモデルを使って、自分でマウスを使って書いた下手くそな文字を認識できるか試してみました。文字の間隔をあえて不均等になるように書いてみたつもりです。
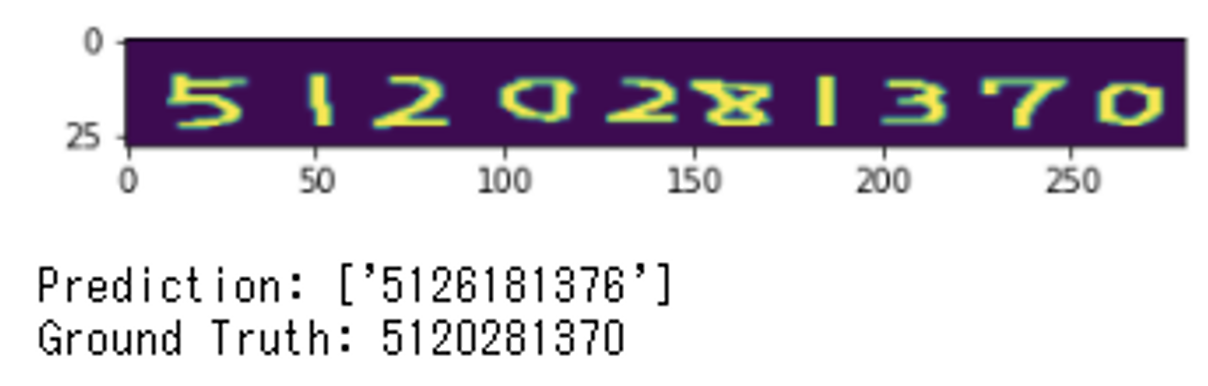
どうでしょうか? 微妙な結果ではありますが結構正解できています。これは、ちゃんとデータを準備して学習すれば、精度アップが期待できるのではないでしょうか。使えるOCRになりそうです!
まとめ
今回はKeras code exampleから、CNN+RNN+CTC損失関数によるシーケンス認証を用いたOCRのサンプルソースを検証してみました。わずか1000件前後のデータ、かつ簡単なモデル構造で、ここまでの結果が出ることには本当に驚きました。
AI OCRのおかげで、ミスが起こりがちだった単純な入力作業やチェック作業から解放されつつある私たちですが、書類のフォーマットだったり、スキャンや撮影条件だったり、その業務の条件によっては既存の製品で対応しきれないこともまだまだ考えられます。そのようなケースで独自データを使ってモデルを学習させたいという場合に、今回のような取り組みが活かせるものと思います。
弊社では、お客様の研究開発や、製品開発をアウトソーシングしていただけます。独自のOCRモデルを作りたいというテーマがあれば、ぜひご相談ください!
Reference
[1] Wekipedia - 光学文字認識
https://ja.wikipedia.org/wiki/%E5%85%89%E5%AD%A6%E6%96%87%E5%AD%97%E8%AA%8D%E8%AD%98
[2] An End-to-End Trainable Neural Network for Image-based Sequence Recognition and Its Application to Scene Text Recognition
https://arxiv.org/abs/1507.05717
[3] THE MNIST DATABASE of handwritten digits
http://yann.lecun.com/exdb/mnist/
[3] Keras Code examples - OCR model for reading Captchas
https://keras.io/examples/vision/captcha_ocr/
その他の記事


