AWS Amazon Lookout for Vision 画像処理 異常検知
2023.01.22 更新
製造業の目視検査を人が行っているのにかえて、AIを使った画像処理で作業を自動化するという事例がよく紹介されますが、当社でもこのようなテーマでPoCをよくご依頼いただきます。
こういったテーマを実現するには、ディープラーニングを活用した画像処理モデルを学習して精度を検証するのですが、実際の画像データがあれば比較的簡単に検証ができるサービスがいくつかの存在しています。
今回はそのようなサービスの中で、Amazon Lookout for Visonを試してみました。
Amazon Lookout for Visionの概要
AmazonにはAmazon Rekognitionというサービスがあり、カスタムラベルを使って画像分類を試すことができますが、Amazon Lookout for Visionは、画像から「製品欠陥を検出し、品質検査を自動化」することに的を絞ったサービスになっていて、いわゆる画像による異常検知、およびセグメンテーションの活用になっています。
こういったテーマのPoC(概念実証)を実施する一般的な流れとしては、①画像収集、②アノテーション、③学習(トレーニング)、④精度検証 のようになりますが、一度で満足いくモデルができることはほとんどなく、これらの作業を何周も繰り返してモデルの精度を高めていくのが通常です。
そのため、これらの作業効率を高めることを目的とした今回のAmazon Lookout for Visionのようなツールは非常に重要になります。
サービスの特徴
公式サイトなどによると、サービスの特徴は以下のとおりです。
Amazon Lookout for Vision 公式サイト
https://aws.amazon.com/jp/lookout-for-vision/
少ない画像枚数で学習できる
わずか30枚のイメージで簡単に作成できる、と公式サイトには書かれています。ディープラーニングモデルの学習というと、何百・何千枚ものデータを集めなければならないイメージがありますが、数十枚レベルで学習できるのは革新的です。
このようなことを自前で実装しようとすると、データ拡張であったり、対照学習のようなさまざまな技術を盛り込む必要がありますが、それらを全く気にすることなく学習データの品質だけに集中できるのはありがたい限りです。
異常検知(二値分類)とセグメンテーションを併用
基本的には異常検知なので、正常か異常かの2つのラベルによる二値分類を実行します。異常データがなくても(正常データだけでも)学習を実行することができますが、異常データが少しでもあるとなお良いとのことです。
これに加えて、異常データについてはさらに細分化したラベルを独自定義してセグメンテーション(領域検出)が実行できます。セグメンテーションなので画像内の異常エリアを正解づけするアノテーションが必要です。
データセットはS3からインポート可能
それなりに多くの画像を扱うことになりますが、あらかじめS3にアップロードしておいた画像を、データセットとしてインポートすることができます。normal、anomaryという名前でフォルダ分けしておけば、自動的に正常、異常のラベルをつけることも可能です。
なお、前述のセグメンテーションのラベル追加、およびアノテーション作業はもちろん手動です。
ハイパーパラメータの最適化も不要
自前でモデルを学習しようとすると、あらかじめ決めなければならないハイパーパラメータをどうするか、どのように最適化するかということが課題になり、グリッドサーチやらその他の最適化手法を取り入れる必要がありますが、Lookoutではいっさい必要ありません。裏で自動で最適化してくれます(ブラックボックスです)。
試してみた(異常検知)
データセットの準備
まずは何といってもデータセットです。今回はMVTec ADから、木製板材のデータセットをお借りしました。
THE MVTEC ANOMALY DETECTION DATASET (MVTEC AD)
https://www.mvtec.com/company/research/datasets/mvtec-ad/
MVTec ADは、工業用の外観検査に特化した異常検知のデータセットです。CVPR2019で公開され、15種類のオブジェクトやテクスチャのカテゴリーに分かれた5,000枚以上の高解像度画像が含まれています。
今回の木製板材データは、板上の穴やキズ、ヒビであったり、黒い節や塗料で色がついている部分がある画像を異常として扱います。

プロジェクト作成
プロジェクトを作成します。適当な名前を入力します。
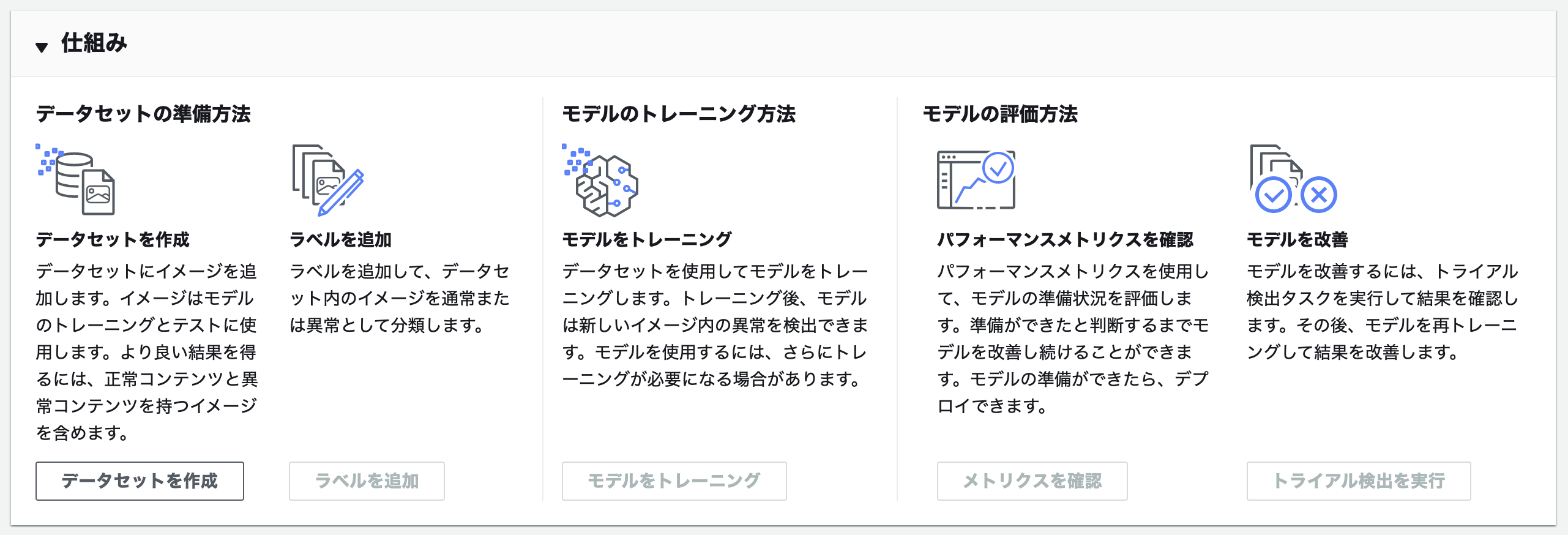
作成が完了すると、プロジェクトの流れを説明する画像が表示されます。
データセット作成
データセットを作成します。あらかじめS3に板材のデータをアップロードしておきましたので、それを使います。
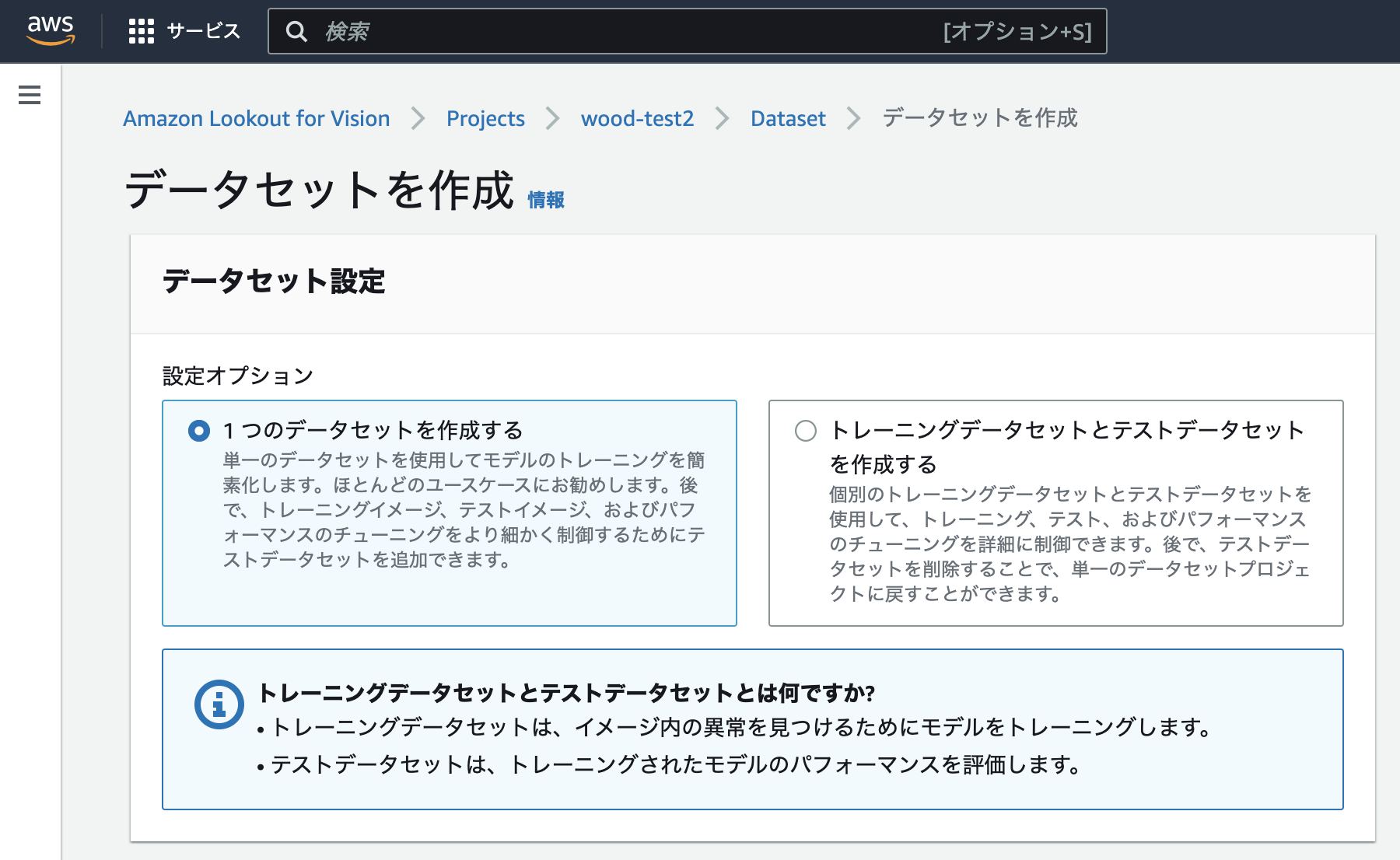
「S3パケットからイメージをインポートする」を選択すると、S3 URIが入力できるとともに、「自動ラベル付け」にチェックをいれるとフォルダ構造にもとづいて自動でラベルをつけてくれます。
S3にアップロードするときのフォルダ構成も案内のとおりに従っておきます。

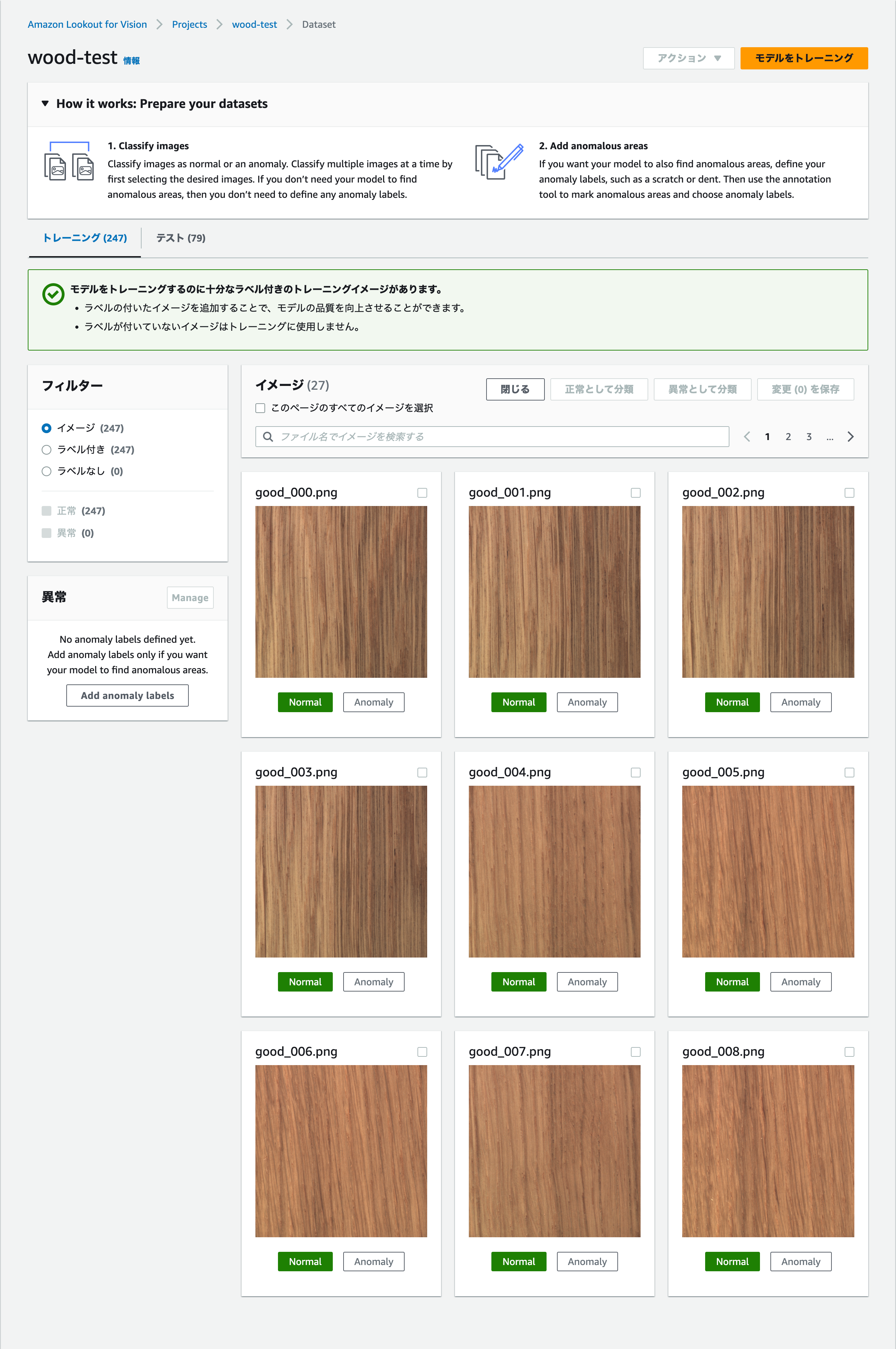
データセット作成完了(ラベル付けも完了)
インポートが完了すると、正常・異常ラベルづけも自動的に終わった状態になります。もちろんここで手動でラベルづけを行うことも可能です。
また画像の追加もできますが、この画面からのアップロードのみになるので、S3を使うことができずやや不便です(アップロードには枚数制限があるのです)。
モデルをトレーニング
全てのトレーニングデータ、テストデータにラベルがついたことを確認したら、「モデルをトレーニング」をクリックします。ハイパーパラメータの設定などは必要ありません。ボタンを1つ押すのみです。
トレーニングが完了すると、テストデータによる精度検証も続けて行ってくれるので、テストデータへのラベルづけも済ませておく必要があります。
今回はトレーニングデータ247枚、テストデータ49枚の規模で、精度が出るまでに約1時間ほどかかりました。
精度検証
トレーニングが完了すると、テストデータで評価された精度が表示されます。どうでしょうか? F1スコアが95.7%ということで、かなり良いのではないでしょうか。テストデータを1枚ずつ、正解・不正解を確認していくことももちろん可能です。
ここから精度を上げるには、データの量や質を見直す地道な作業に入っていきます。
試してみた(セグメンテーション)
次に、二値分類による異常検知に加えて、セグメンテーションを試していきます。
異常ラベルを細分化
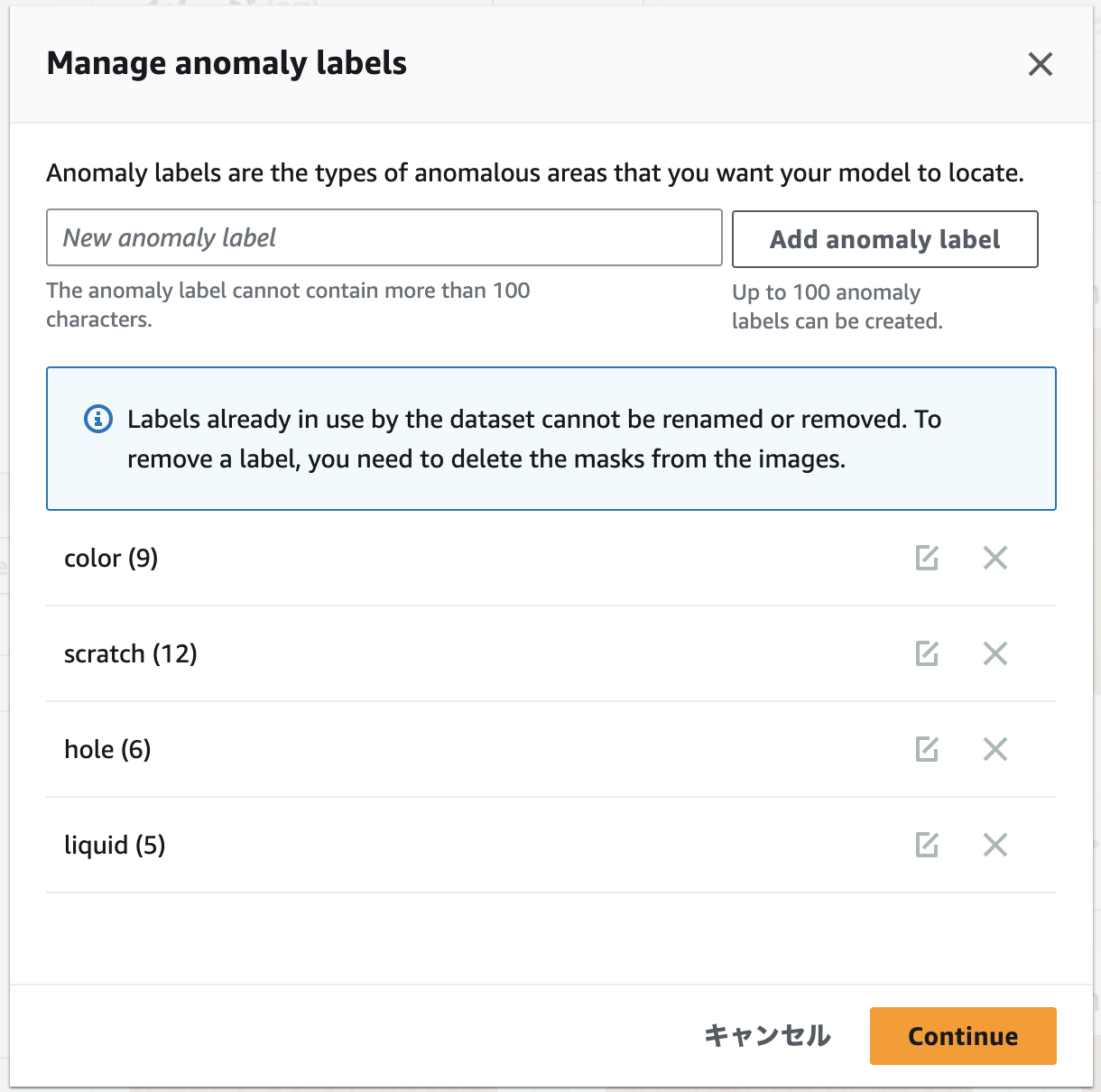
異常の「Manage」をボタンをクリックして、異常の種類ごとにラベルを細分化します。MVTec ADのデータに合わせて、このようにラベルを定義します。
アノテーション
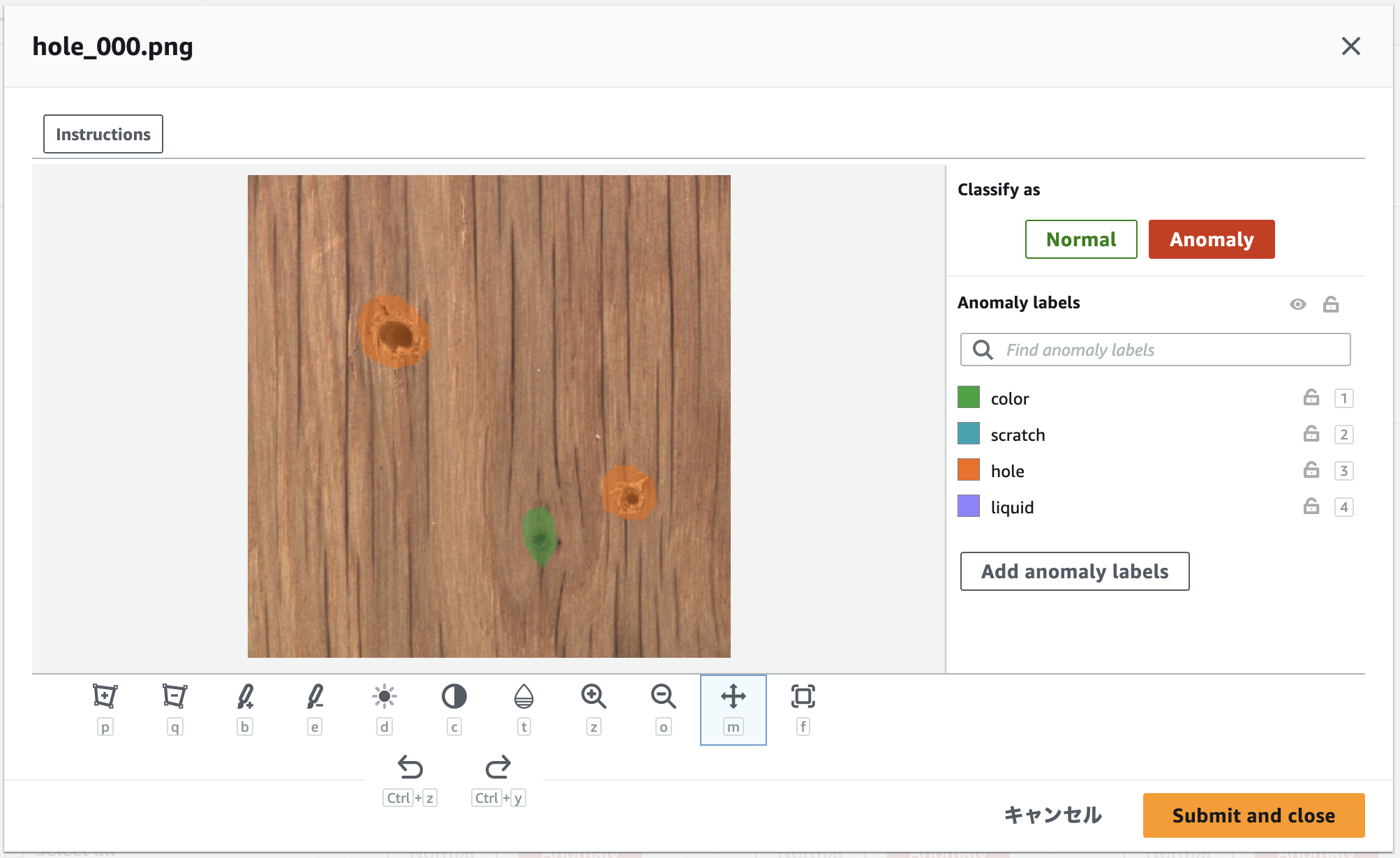
異常画像を1枚ずつ表示し、下図のように異常部分をラベルに合わせて色塗りしていきます。セグメンテーションのアノテーション作業は、本当に大変です。
※ ここの画面のレスポンスが若干悪く、一度アノテーションしたはずの領域が描画されないなど、スムーズに作業できない点が少し気になりました。
データ数が足りず、、残念
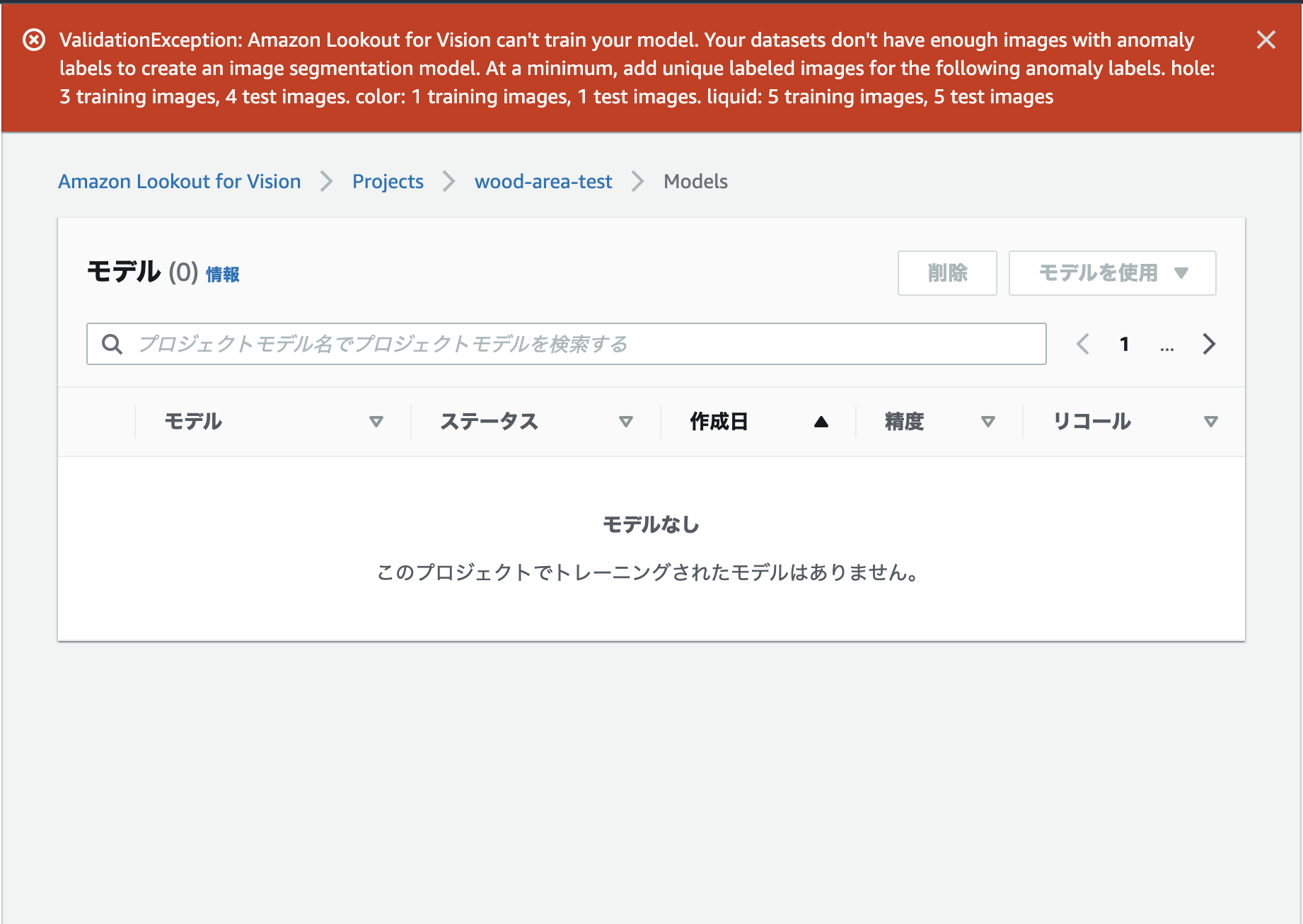
板材データの異常画像30枚の色塗りをせっせと終えて、いざトレーニングを実行すると、ラベルごとの画像枚数が足りないというエラーが発生。木製板材データではこれ以上枚数を増やすことができず、やむ無く断念しました。
何とかアノテーションを始める前に教えていただくことはできませんでしょうか。
改めて別のデータセットで試みると
悔しいので別のデータセットを使ってセグメンテーションを実行してみました。こちらは無事にトレーニングが完了し、精度が表示されました。こちらのF1スコアもかなり良いです。
そして、肝心のセグメンテーションの結果もかなり良いようです。
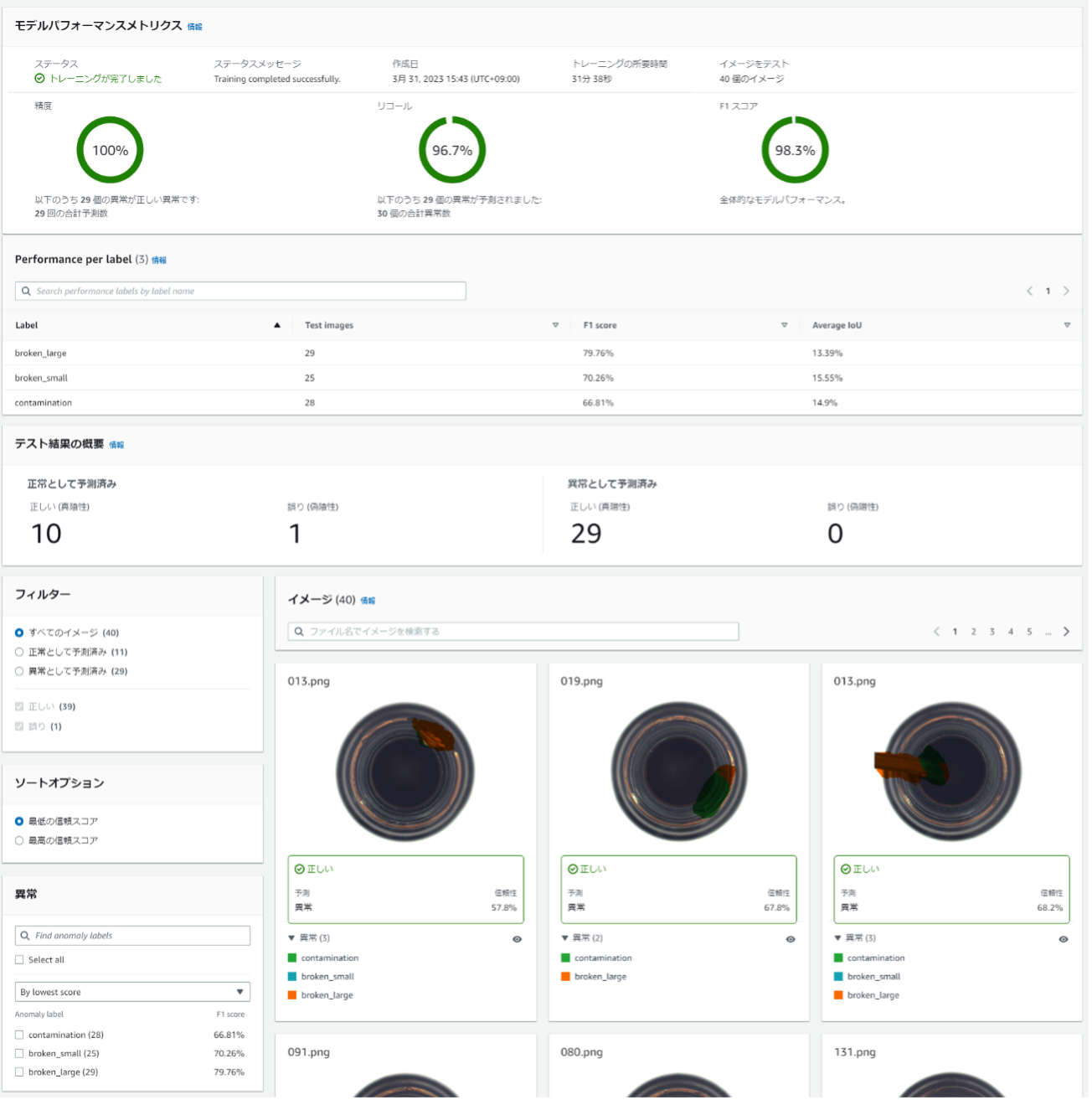
この他、テストデータを別途用意してモデルの汎化性能を検証する機能もあります。この場合、実はさらにその予測が間違っているところがあれば、それをモデルにフィードバックする機能もあるらしいですが、今回使用するデータセットにおいては追加で使用できる異常データがないため、今回の検証はここまでにしたいと思います。
できたモデルを運用するには
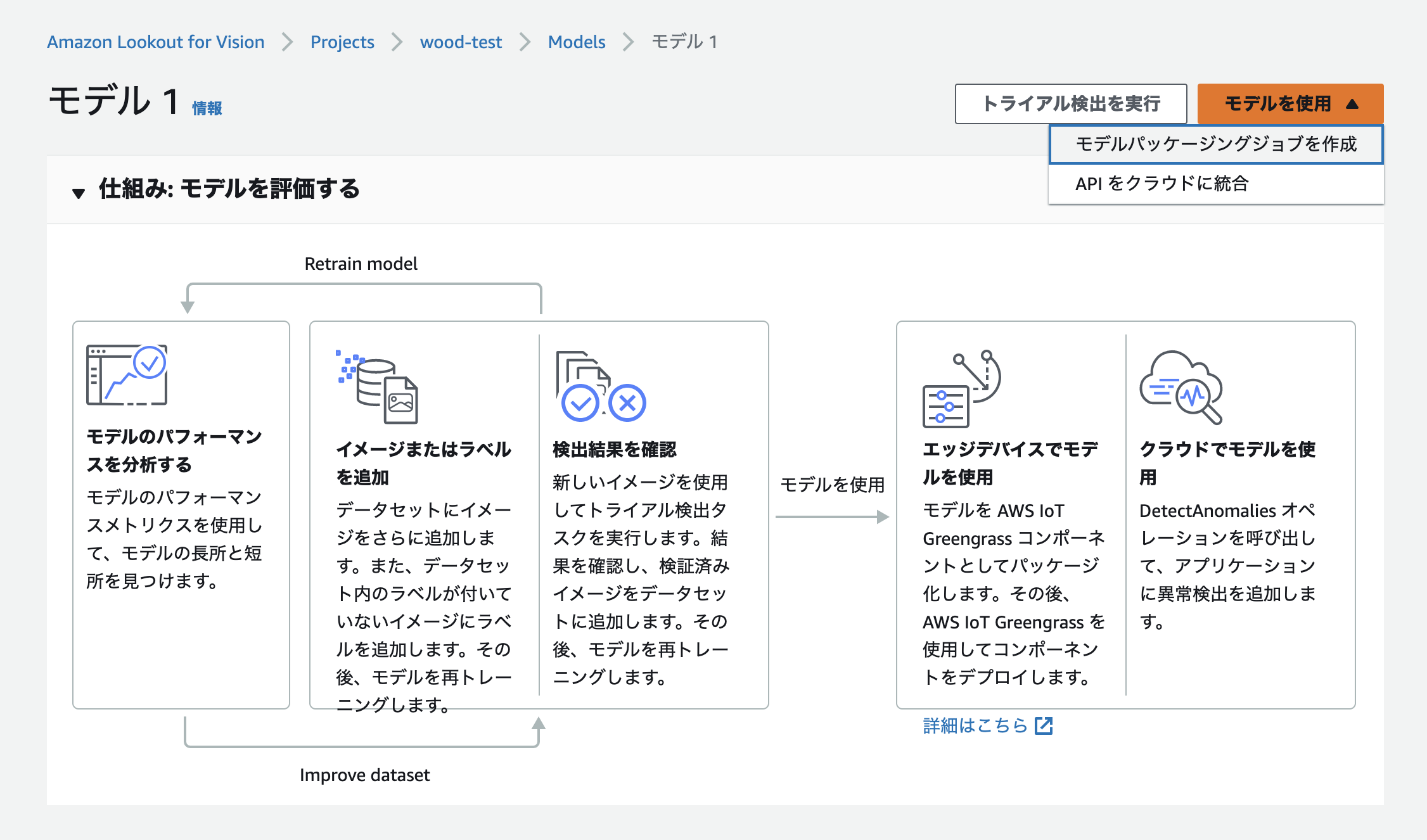
満足いく精度のモデルが作成できたら、それをそのまま運用で使用する方法も用意されています。
モデルの精度結果の画面から「モデルを使用」ボタンをクリックすると、「モデルパッケージングジョブを作成」と「APIをクラウドに統合」の2つから選択できます。
前者は、AWS IoT Greengrassという別サービスに対応していて、モデルをエッジで動作できるコンポーネントに変換して使用するパターンです。製造業の工場などで高いリアルタイム性が求められる、ネットワーク帯域の条件などで第1選択肢になるでしょう。
逆に後者は、モデルをクラウドで動作させるパターンに対応しています。AWL CLIを使って動作させるようです。この場合は、推論のたびにクラウドに画像データを送ることになり、実際の運用では前者を優先することのほうが多いのではないかと思います。
まとめ
今回は、Amazon Lookout for Visionで、実際の画像データを使って異常検知を試してみました。 非常に少ない画像で、ハイパーパラメータのチューニングも気にする必要なく、かなり高精度なモデルを得ることができました。
実際の開発でも、多くの画像が得られない(特に異常データにおいては)というケースが非常に多く、途中でプロジェクトを断念することも多い中で、少量データで試行錯誤を何回もまわしやすいこのようなツールは、非常に有用であると感じました。
モデルを運用で使用する方法も、エッジとクラウドと両者用意されていて非常に使いやすく、採用できるケースが多いだろうと思います。
今後はその他のサービスも試していって、メリット・デメリットを踏まえて提案できるようになっていきたいですね。
Reference
[1] Amazon Lookout for Vision
https://aws.amazon.com/jp/lookout-for-vision/
[2] THE MVTEC ANOMALY DETECTION DATASET (MVTEC AD)
https://www.mvtec.com/company/research/datasets/mvtec-ad/
その他の記事






